Documenting your database with SchemaSpy
Why?
I'm a big fan of auto generating documentation to help visualise and understand complex artefacts such as codebases. In my new workplace, we also have a large complex database and not much in the way of support for understanding it or it's history.
This complexity effects productivity in a number of ways:
- It takes longer than it should to parse and understand a database, especially through tools such as Postgres Admin and the command line
- It takes longer to support other colleagues to understand and use the database
- Poor understanding leads to poor coding and bugs
A good piece of documentation supports collaboration and learning.
How can SchemaSpy help?
SchemaSpy (http://schemaspy.org/) is a database documenting utility written in Java that analyses your schema and generates an HTML report of your database schema, including some very useful Entity Relationship diagrams.
There are a couple of ways to run SchemaSpy. Here we'll look at running the utility using docker. See the image page @ https://hub.docker.com/r/schemaspy/schemaspy/.
The image contains drivers for:
- mysql
- mariadb
- postgresql
- jtds
The images has 3 volumes:
- /drivers (if you want to override the included drivers, or add another driver)
- /output need to host-mount this to get any output (must be writable by other (safes bet))
- /config if you want to add schemaspy.properties file.
Configuration properties and command line options are documented on the readthedocs site @ https://schemaspy.readthedocs.io/en/latest/
To run SchemaSpy using the image you can use the command below.
docker run -v "$PWD:/output" schemaspy/schemaspy:latest [options]
Example
So in our example, i'll be connecting to a local database called world-db (see https://github.com/ghusta/docker-postgres-world-db) and providing a config file
config/schemaspy.properties
schemaspy.t=pgsql
schemaspy.host=host.docker.internal
schemaspy.port=5432
schemaspy.db=world-db
schemaspy.u=world
schemaspy.p=world123
schemaspy.schemas=public
Now that we have a configuration file we can run SchemaSpy via Docker
docker run -v "${PWD}\target:/output" -v "${PWD}\config:/config" schemaspy/schemaspy:latest -configFile /config/schemaspy.properties -noimplied -nopages -l
The docker command will output to the console whilst executing...
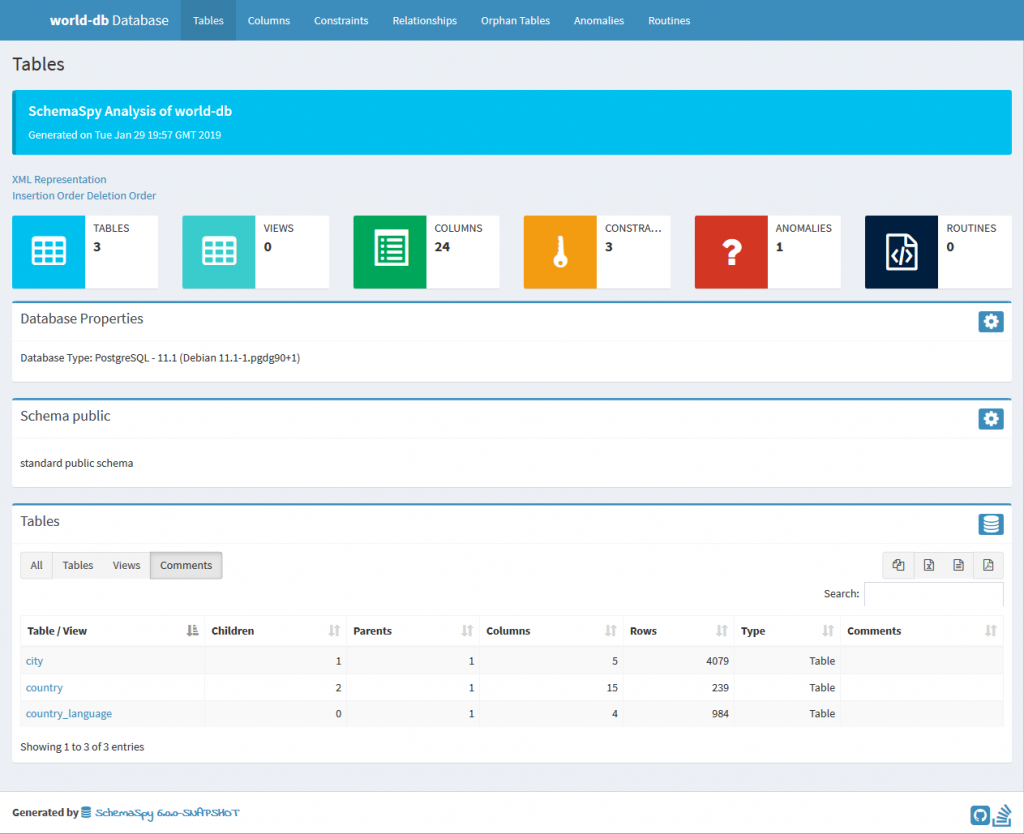
Once complete, the HTML documentation will be available in the output directory. The HTML can be explored to see all the table information and relationships.
Screenshot of the output
![]()
Further thoughts
Running from the command line gives you an excellent opportunity to integrate this into your CI pipelines so that it can be regularly updated.
One thing the documentation will certainly highlight is a lack of comments on your tables, views and functions. Yes, you can probably derive meaning from column names but often a simple comment is nicer ;)
Got suggestions for any alternatives or power user tips, why not comment below?